AI Agents for Beginners - 10. AI Agents in Production: Observability & Evaluation
How to move AI agents from prototype to production — observability with traces and spans, key metrics, OpenTelemetry instrumentation, offline/online evaluation, cost management, and a real expense claim demo.
June 9, 2026
AI Agents for Beginners - 10. AI Agents in Production: Observability & Evaluation
이 글은 Microsoft의 AI Agents for Beginners 강좌 Lesson 10을 기반으로 정리한 내용입니다.
AI Agent가 실험적 프로토타입에서 실제 애플리케이션으로 이동할 때, 에이전트의 동작을 이해하고 성능을 모니터링하며 출력을 체계적으로 평가하는 능력이 중요해집니다.
이 레슨의 목표는 "블랙박스" 에이전트를 투명하고 관리 가능하며 신뢰할 수 있는 시스템으로 전환하는 지식을 제공하는 것입니다.
Traces and Spans
| 개념 | 설명 |
|---|---|
| Trace | 시작부터 끝까지의 전체 에이전트 태스크 (예: 사용자 쿼리 처리 전체) |
| Span | Trace 내 개별 단계 (예: LLM 호출, 데이터 검색, tool 실행) |
Trace & Span HierarchyMermaidflowchart TD T["Trace\n전체 에이전트 태스크\n(사용자 쿼리 처리)"] T --> S1["Span: LLM Call\n모델 추론"] T --> S2["Span: Tool Call\nget_flight_info()"] T --> S3["Span: Tool Call\nget_activity_suggestions()"] T --> S4["Span: LLM Call\n최종 응답 생성"] S1 -->|"latency, tokens"| M1["Metrics"] S2 -->|"latency, result"| M2["Metrics"] S3 -->|"latency, result"| M3["Metrics"] S4 -->|"latency, tokens"| M4["Metrics"]
관측성이 없으면 AI Agent는 내부 상태와 추론이 불투명한 "블랙박스"처럼 느껴집니다.
관측성을 갖추면 에이전트는 유리 상자(glass box)가 되어 신뢰 구축과 의도대로 동작하는지 확인이 가능해집니다.
관측성을 갖추면 에이전트는 유리 상자(glass box)가 되어 신뢰 구축과 의도대로 동작하는지 확인이 가능해집니다.
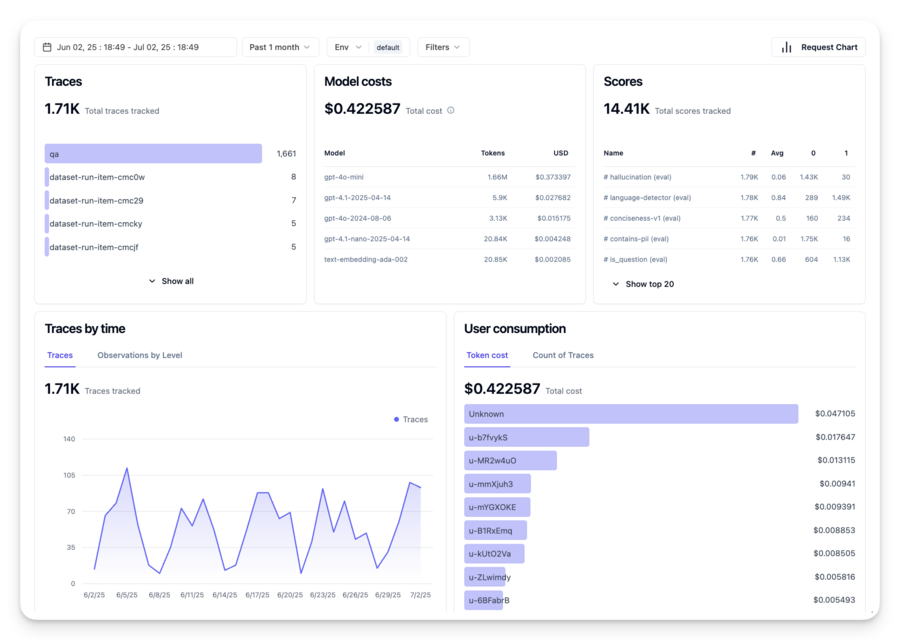
Why Observability Matters in Production Environments
프로덕션 환경에서 관측성은 "있으면 좋은 것"이 아닌 필수 기능입니다:
| 이유 | 설명 |
|---|---|
| Debugging & Root-Cause Analysis | 복잡한 다중 LLM 호출, tool 상호작용, 조건부 로직에서 에러 원인을 trace로 정확히 파악 |
| Latency & Cost Management | API 호출별 지연·비용을 정밀 추적해 느리거나 비싼 연산을 식별하고 최적화 |
| Trust, Safety & Compliance | 에이전트 행동·결정의 감사 추적 제공 — prompt injection, 유해 콘텐츠, PII 오처리 감지 |
| Continuous Improvement Loops | 프로덕션 인사이트가 오프라인 실험을 개선하는 피드백 루프 형성 |
Key Metrics to Track
에이전트 동작을 모니터링하기 위해 추적해야 할 핵심 메트릭:
| 메트릭 | 설명 | 활용 예 |
|---|---|---|
| Latency | 에이전트 응답 속도 | 20초 걸리는 에이전트 → 더 빠른 모델 사용 또는 병렬 호출로 개선 |
| Costs | 에이전트 실행당 비용 | 5번 LLM 호출 시 품질 향상이 미미하면 호출 횟수 줄이거나 저렴한 모델 사용 |
| Request Errors | API 오류·tool 호출 실패 수 | LLM provider A 다운 시 provider B로 fallback 설정 |
| User Feedback | 명시적 평가 (👍/👎, ⭐1-5) | 지속적 부정 피드백 = 에이전트 미작동 신호 |
| Implicit User Feedback | 반복 질문, 즉시 재작성, retry 클릭 | 동일 질문 반복 = 에이전트가 기대한 응답을 못하는 신호 |
| Accuracy | 올바른·바람직한 출력 빈도 | trace에 "succeeded"/"failed" 레이블 → 성공률 추적 |
| Automated Evaluation Metrics | LLM 기반 자동 스코어링 | RAGAS for RAG, LLM Guard for safety |
Instrument your Agent
에이전트 계측(instrumentation)의 목표는 코드가 trace와 metrics를 내보내도록 만들어 관측성 플랫폼에서 캡처·처리·시각화할 수 있게 하는 것입니다.
OpenTelemetry
OpenTelemetry (OTel)은 LLM 관측성을 위한 업계 표준으로 자리잡고 있습니다.
Microsoft Agent Framework는 OpenTelemetry와 네이티브로 통합됩니다:
Microsoft Agent Framework는 OpenTelemetry와 네이티브로 통합됩니다:
otel_instrumentation.pypython
Manual Span Creation
자동 계측이 기준선을 제공하지만, 더 세밀한 정보가 필요할 때 수동으로 span을 생성할 수 있습니다.
user_id, session_id, model_version 같은 커스텀 속성을 span에 추가해 디버깅·분석에 활용합니다:manual_span_langfuse.pypython
Building an Observable Agent
Travel Agent에 timing을 추가해 간단한 관측성을 구현합니다.
프로덕션에서는 OpenTelemetry 같은 tracing 백엔드와 통합합니다:
프로덕션에서는 OpenTelemetry 같은 tracing 백엔드와 통합합니다:
setup.pypython
travel_tools.pypython
observable_agent.pypython
Observable Agent FlowMermaidflowchart LR User["User Query\n'Plan a day trip in Paris'"] --> Timer["start_time = time.time()"] --> Agent["TravelAgent"] Agent --> F["get_flight_info('Paris')"] Agent --> A["get_activity_suggestions('Paris')"] F & A --> LLM["LLM\n응답 종합"] LLM --> Stop["elapsed = time.time() - start_time"] Stop --> Out["Response (elapsed s)\n+ 프로덕션: OTel 백엔드 전송"]
Agent Evaluation
관측성은 메트릭을 제공하고, 평가(Evaluation)는 그 데이터를 분석해 에이전트의 성능을 판단하고 개선 방법을 결정하는 프로세스입니다.
AI Agent는 비결정적이고 업데이트·모델 드리프트로 변화할 수 있으므로 정기적인 평가가 필수입니다.
AI Agent는 비결정적이고 업데이트·모델 드리프트로 변화할 수 있으므로 정기적인 평가가 필수입니다.
평가는 두 가지 범주로 나뉩니다: Offline Evaluation과 Online Evaluation.
Offline Evaluation
통제된 환경에서 테스트 데이터셋으로 에이전트를 평가합니다.
기대 출력을 알고 있는 큐레이션된 데이터셋을 사용하고, 개발 중(CI/CD 파이프라인 포함)에 실행해 개선을 확인하거나 회귀를 방지합니다.
기대 출력을 알고 있는 큐레이션된 데이터셋을 사용하고, 개발 중(CI/CD 파이프라인 포함)에 실행해 개선을 확인하거나 회귀를 방지합니다.
- 장점: 반복 가능하고 ground truth가 있어 명확한 정확도 메트릭 확보
- 핵심 과제: 테스트 데이터셋을 포괄적으로 유지하고 실제 시나리오로 지속 업데이트
Online Evaluation
라이브·실제 환경에서 에이전트를 평가합니다.
실제 사용자 상호작용의 성능을 모니터링하고 결과를 지속적으로 분석합니다.
실제 사용자 상호작용의 성능을 모니터링하고 결과를 지속적으로 분석합니다.
- 장점: 실험실 환경에서 예상하지 못한 것들을 포착 — 모델 드리프트, 예상치 못한 쿼리 패턴
- 방법: 암묵적·명시적 사용자 피드백 수집, shadow test, A/B 테스트
Combining the two
온라인·오프라인 평가는 상호 배타적이 아니라 상호 보완적입니다:
Evaluation LoopMermaidflowchart LR OE["Offline Evaluation\n테스트 데이터셋으로 평가"] --> Deploy["Deploy\n프로덕션 배포"] --> OL["Online Monitoring\n실제 사용자 상호작용 추적"] --> Collect["Collect Failures\n새 실패 케이스 수집"] --> Add["Offline Dataset 보강\n엣지 케이스·신규 패턴 추가"] --> Refine["Refine Agent\n프롬프트·모델·로직 개선"] Refine --> OE
Evaluation Patterns
프로덕션에서 흔히 쓰이는 패턴은 두 번째 에이전트를 평가자로 활용하는 것입니다.
평가자 에이전트는 기준 항목별로 주 에이전트의 응답을 스코어링합니다:
평가자 에이전트는 기준 항목별로 주 에이전트의 응답을 스코어링합니다:
evaluator_agent.pypython
Evaluator Agent PatternMermaidflowchart TD User["User Query"] --> Primary["Primary Agent\n(TravelAgent)"] Primary --> Resp["Agent Response"] Resp --> Eval["Evaluator Agent\n(ResponseEvaluator)"] Eval --> Score["Scores\nCompleteness · Accuracy · Helpfulness · Overall"] Score --> Gate{품질 기준 통과?} Gate -->|"Pass"| Deliver["사용자에게 전달"] Gate -->|"Fail"| Flag["플래그 → 개선·재시도"]
Common Issues
프로덕션 AI Agent 배포 시 자주 발생하는 이슈와 해결책:
| 이슈 | 해결책 |
|---|---|
| 일관성 없는 태스크 수행 | 프롬프트를 구체화해 목표를 명확히. 태스크를 하위 태스크로 분해하고 멀티에이전트로 처리 |
| 무한 루프 | 명확한 종료 조건 정의. 복잡한 추론·계획 태스크는 추론 특화 대형 모델 사용 |
| tool 호출 성능 저하 | 에이전트 시스템 외부에서 tool 출력을 테스트·검증. 파라미터·프롬프트·tool 명칭 개선 |
| 멀티에이전트 불일치 | 각 에이전트 프롬프트를 명확·구체적으로. "routing" 또는 controller 에이전트로 계층적 구조 구축 |
관측성이 갖춰지면 이러한 이슈를 훨씬 효과적으로 식별할 수 있습니다. trace와 메트릭이 에이전트 워크플로우의 정확한 문제 위치를 파악하는 데 도움을 줍니다.
Managing Costs
프로덕션 AI Agent 비용 관리 전략:
| 전략 | 설명 |
|---|---|
| Using Smaller Models | SLM은 특정 agentic 유스케이스에서 잘 동작하며 비용을 크게 줄임. 간단한 태스크(인텐트 분류, 파라미터 추출)에 SLM, 복잡한 추론에만 대형 모델 사용 |
| Using a Router Model | LLM/SLM 또는 serverless function으로 복잡도에 따라 최적 모델에 요청 라우팅. 간단한 쿼리 → 작고 빠른 모델, 복잡한 추론 → 대형 모델 |
| Caching Responses | 공통 요청·태스크를 캐시해 유사 요청이 에이전트 시스템을 통과하기 전에 응답 제공. 자주 묻는 질문·공통 워크플로우 비용을 크게 절감 |
Cost Management: Router Model StrategyMermaidflowchart TD Req["User Request"] --> Router["Router Model\n(LLM/SLM/serverless)"] Router --> Complexity{복잡도 분류} Complexity -->|"Simple\n인텐트 분류·파라미터 추출"| SLM["SLM\n(GPT-4o-mini 등)\n저비용·고속"] Complexity -->|"Complex\n복잡한 추론·계획"| LLM["Large Model\n(GPT-4o 등)\n고성능"] Complexity -->|"Cached\n자주 묻는 질문"| Cache["Cache\n즉시 응답\n비용 0"] SLM & LLM & Cache --> Response["Final Response"]
Lets see how this works in practice
실전 예제로 영수증 이미지 OCR → 경비 청구 이메일 생성 파이프라인을 구현합니다.
멀티에이전트
멀티에이전트
WorkflowBuilder로 OCR Agent와 Email Agent를 연결합니다.Define Expense Models
expense_models.pypython
Defining Tools
expense_tools.pypython
Processing Expenses
expense_workflow.pypython
Expense Claim WorkflowMermaidflowchart LR Receipt["receipt.jpg\n영수증 이미지"] --> OCR["OCRAgent\nload_receipt_image()\n이미지 → base64 인코딩"] OCR --> Parse["영수증 텍스트 분석\ndate|description|amount|category\n세미콜론 구분 형식"] Parse --> Email["EmailAgent\ngenerate_expense_email()\nExpenseFormatter.parse_expenses()"] Email --> Mail["경비 청구 이메일\nDear Finance Team...\nTotal Amount: $xxx"]
Summary
Lesson 10 SummaryMermaidflowchart LR Root["AI Agents\nin Production"] Root --> Obs["Observability"] Root --> Eval["Evaluation"] Root --> Cost["Cost Management"] Obs --> O1["Traces & Spans"] Obs --> O2["Key Metrics\nLatency·Cost·Error·Feedback"] Obs --> O3["OpenTelemetry\n+ Manual Spans"] Eval --> E1["Offline Evaluation\n통제된 테스트 데이터셋"] Eval --> E2["Online Evaluation\n실제 사용자 모니터링"] Eval --> E3["Evaluator Agent\n자동 품질 스코어링"] Cost --> C1["Smaller Models (SLM)"] Cost --> C2["Router Model"] Cost --> C3["Caching"]
- Traces & Spans로 에이전트를 "블랙박스"에서 "글래스박스"로 전환해 디버깅·최적화를 가능하게 합니다
- Latency·Cost·Request Errors·User Feedback 등 핵심 메트릭을 추적해 에이전트 건강 상태를 종합적으로 파악합니다
- Offline Evaluation으로 배포 전 기준선을 확보하고, Online Evaluation으로 실제 환경의 드리프트와 예상치 못한 패턴을 포착합니다
- Evaluator Agent 패턴으로 주 에이전트 응답을 자동 품질 게이팅해 회귀를 방지합니다
- Router Model·SLM·Caching으로 비용을 관리하면서 필요한 태스크에 고성능 모델을 유지합니다